¡Qué mezcla imposible! Se podría pensar que algo tan numérico y duro como los macrodatos no puede ser nunca leído desde una perspectiva cultural que parte normalmente desde una subjetividad. Y sin embargo…Les cuento como llegué a esta idea.
En mi vida personal, me pasa que me muevo por lo menos en tres idiomas: español, italiano e inglés…Y ahora está entrando un cuarto, el catalán. Y qué pasa, que me encanta “mirar por las ventanas” que ofrecen los idiomas. ¿Cómo se dice ésto en español? ¿Por qué no hay un término idéntico en italiano, no obstante ser un idioma tan cercano estructuralmente?¿Por qué en inglés tienen un término para denominar un fenómeno cuya traducción (y existencia) es imposible en italiano y español?
En mi exploración del tema de la interculturalidad, que aparece en mi tesis y en uno de los trabajos que más me gustó realizar “A class-room with a View“, ya exploraba el problema de la cultura como proceso de construcción continua que plasma el lenguaje; y este a su vez, da forma a la comprensión de las cosas y al hacer en el mundo. Por lo tanto, no es extraño que una de mis actividades preferidas, al dar forma a algún concepto o idea, fuera buscar las versiones en distintos idiomas de un mismo libro (Por ejemplo, la versión en inglés de “Pedagogia do Oprimido” de Paulo Freire). Pero más divertido aún ha sido buscar un mismo concepto en Wikipedia, en los tres idiomas que conozco (en cualquier caso, de matriz occidental) y observar con mucha curiosidad las diferencias de configuración de un mismo concepto desde su historia. Veamos: Wikipedia ha sido la panacea del Web Social. El Web de la colaboración, de la construcción de conocimiento abierto. Y la cosa que ya observaba en éste web, era una increíble persistencia de diferencias de mirada cultural sobre un mismo objeto. Pongamos el caso del término “MOOC” (Massive Open Online Courses): en inglés, nos sorprenderemos por la riqueza de referencias y el detalle de la historia del término. Se observa la preocupación por comprender la productividad de los MOOC y sus aplicaciones para el cambio de los modelos de business en la educación superior, así como su aplicación al campo de la formación profesional/industrial. Hay un apartado dedicado a comparar los principales proveedores americanos (eDX, Coursera, uDacity) y no se habla en ningún caso de plataformas europeas o de otros orígenes, ni otras experiencias fuera del contexto NordAmericano. Miríada, la gran plataforma de habla hispana, no es mencionada nunca en este artículo. Pasemos al español: en este caso la información es detallada, se diferencias los cMOOCs y los xMOOCs que han generado inicialmente gran debate en cuanto al modelo y conceptualización pedagógica subyacente (conectivista una y comportamentista la otra; altamente compleja la primera, más automatizada y supuestamente eficaz la segunda). Y claro está, se dedica un buen apartado para hablar de los MOOC en Latinoamérica. Terminemos nuestra exploración en italiano. La información brindada es mínima, con un sólo artículo en italiano dedicado al tema, no obstante el hecho que conociendo el panorama de la educación superior en Italia yo misma pueda afirmar que el debate sobre los MOOCs se activó tempranamente, se le dedicaron varios artículos académicos, algún libro, representaciones de proyectos europeos (por ejemplo EMMA y su relación con la plataforma Federica) y una plataforma nacional para recoger MOOCs de origen italiano: EDUOPEN. El análisis de las causas sería demasiado complejo para ser abarcado en un solo post. Pero desde ya podemos asumir que las diferencias se basan en la configuración diferenciada de los fenómenos sociales en los distintos mundos lingüísticos y culturales de referencia. Y que cuando decimos MOOCs, a un angloparlante, a un hispano y a un italiano se le representarán experiencias e informaciones más bien diversificadas.
Si, el web, por más abierto y social que sea, está atravesado por los lugares del lenguaje y la cultura.
A aquellos que hablen más de un idioma, los invito a ejercitarse en estas búsquedas y comparar. Los resultados de visibilidad e invisibilización de fenómenos locales en lo que se denomina “internacional” (es decir, occidental y anglófono) serán sorprendentes.
Hemos llegado hoy a la inteligencia artificial y a los macrodatos como componente molecular de nuestra actividad en contextos digitales. Pero no me voy a ocupar de cómo se definen en Wikipedia. De lo que me voy a ocupar es de un simple ejercicio de comprensión de cómo los macrodatos también están atravesados culturalmente y conllevan una multiplicidad de perspectivas, fenómeno similar al observado por los más humanos constructores de conocimiento detrás de Wikipedia.
En este punto, voy a seguir el análisis planteado por Seth Stephen-Davidowitz en su libro “Everybody Lies: Big Data, New Data and what the Internet Can Tell Us About Who We Really Are”. En su calidad de “data-scientist” y psicólogo, empleado en Google, Stephen-Davidowitz nos enseña cómo las encuestas relevan datos incompletos y frecuentemente falseados por la impelente necesidad humana de aceptación social. No confesamos en una encuesta nuestros hábitos más privados, ni nuestras fantasías más extremas. Y aparentemente mentimos en lo menos extremo también, casi emerge en este trabajo como la mentira es algo cotidiano. Sin embargo, nos aclara Stephen-Davidowitz,
“…sometimes we type our uncensored thoughts into Google, without much hope that it will be able to help us. In this case, the search window serves as a kind of confessional“
“…algunas veces tipeamos nuestros pensamientos sin censuras en Google, sin mucha esperanza de que eso nos pueda ayudar. En ese caso, la ventana del buscador se comporta como una especie de confesionario (mi énfasis)“
Según este autor Google (y otros colosos de nuestra vida digital como Facebook o Twitter) recogen una tal cantidad de datos sobre nosotros mismos que las mentiras que emergen a través de los varios métodos de investigación social quedan develadas a través de los macrodatos. No puedo no dar razón a Stephen-Davidowitz a partir de su brillante ex-cursus y de los muchísimos ejemplos que plantea.
Sin embargo, los ejemplos abundan en casos de búsqueda y problemáticas americanas, y mi pregunta va a la diversidad cultural, la misma que habría observado a través de Wikipedia. Stephen-Davidowitz nos regala las bases para este enfoque (una perspectiva cultural de los big data) pero no la plantea, porque no siente la necesidad: se mueve en su propia matriz cultural.
Hagamos el ejercicio más simple de interacción con “Big Data” que se nos puede ocurrir: usando el navegador de Google, busquemos un par de palabras que tienen humana significatividad, es decir, “Quiero” ; “I want”; “Voglio”.
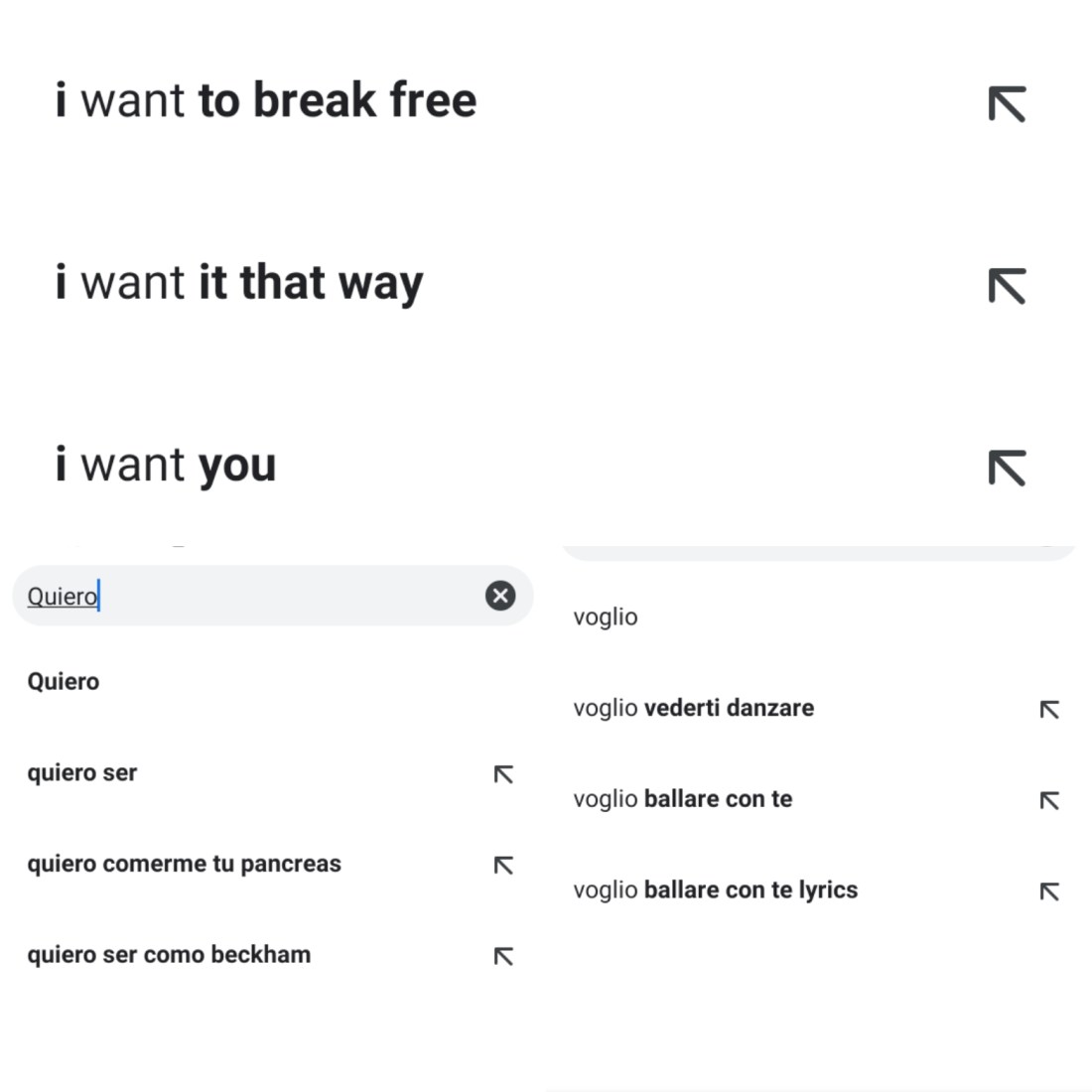
La primera observación es hilarante. Como sabemos, el algoritmo de Google lleva a proponer aquello que es más buscado por una gran mayoría de personas. Por lo que parece, millones de personas angloparlantes están muy preocupadas por ampliar sus grados de libertad (I want to break free, I want it that way) y encontrar a ese partner que cambiará sus vidas. Mucho más sometidos a sistemas patriarcales y jerárquicos, los hispanos quieren encontrar su camino a la libertad a través del querer ser algo (antes que querer cualquier otra cosa) y en particular ser alguien rico (Beckham). Lo del páncreas: no se horroricen, se trata de un sentimental libro y posterior manga que probablemente esté haciendo derramar ríos de lágrimas a más de un latino telenovelero. (y volvemos al tema del amor). ¿En italiano? Víctimas de una crisis política llena de extremismos y una pérdida de vista del futuro próximo y lejano, los italianos parecen encontrar su vía de escape en el baile y la música ligera. Fiesta.
Ahora, permitanme estas banalísimas interpretaciones cuyo único objetivo era hablar con un poco de humor de algo que sí me preocupa sacar a la luz: el hecho de que los macrodatos trazan diversidades. Que la internacionalidad de sus soluciones no es tal. Que los algoritmos, en el último de los casos, explicarán la matriz cultural de quien los haya creado, y de los modelos estadísticos y las poblaciones relacionadas sobre los que habrán sido aplicados.
Hagamos otro experimento de navegación de macrodatos, usando Google Ngram, la enorme máquina de minería de textos (text mining) literarios. Busco las palabras “hombre-mujer”, “man-woman”, “uomo-donna” en libros que han sido publicados desde el 1800 hasta el 2000 (rango dado por Ngram).
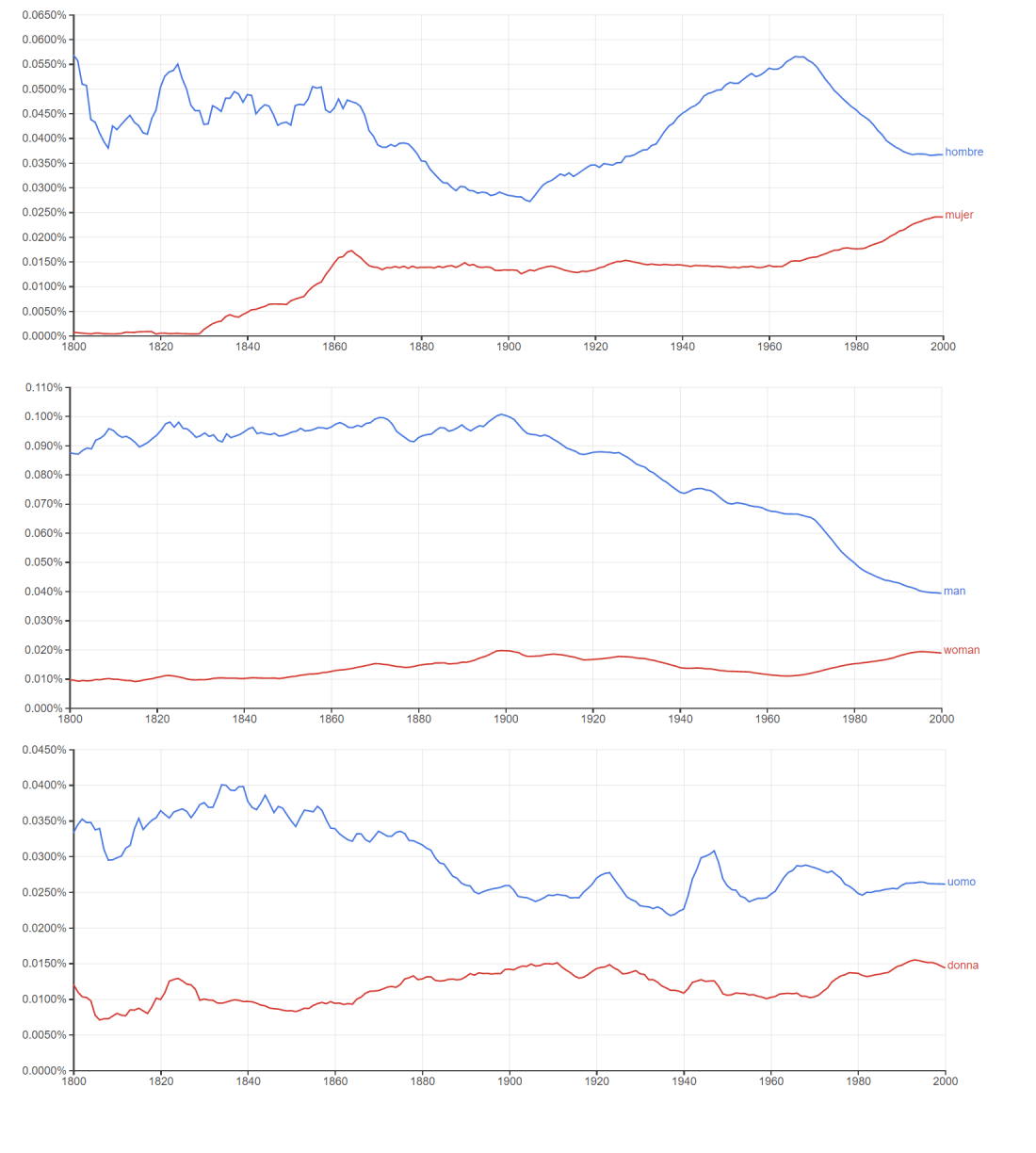
Lo que vemos no nos sorprende demasiado: mucha más frecuencia del término hombre-man-uomo que del término mujer-woman-donna. Y sin embargo, es curioso observar que la evolución no es exactamente la misma (por ejemplo el crecimiento más importante del término mujer en el idioma español, o la relación entre frecuencia de términos más cercana en el idioma italiano que en el idioma inglés). No me voy a ocupar de interpretar esta búsqueda, pero sí de decir que si no aplicara una lectura de diversidad lingüística y cultural, podría quedarme con una interpretación de los macro-datos que es incompleta.
Mi reflexión me lleva por los meandros del problema de decontextualización de las soluciones edtech y de las soluciones educativas en general. El riesgo de sistemas de macrodatos y de ciencia de datos importados podría conllevar a un enorme bias en su aplicación. Pero esta no es mi ocupación, no vengo ni de la sociología, ni de la economía ni de la política. Me compete advertir que en el ámbito de la educación, se deberían experimentar con todas las personas que aprenden experiencias de navegación intercultural de los macrodatos, analíticas y paneles de mando visuales (o “dashboards”) para comprender, desde los niveles de competencia que tengamos, el concepto de macrodato, de algoritmo y de cuantificación.
Los datos no son objetivos. No son naturales. Hay profundos fenómenos culturales entramados en sus tecnoestructuras. Y es mejor que lo tengamos claro.
